For the last five years, building a world-class AI system has followed a straightforward formula: train the largest model you can afford on as much high-quality internet data as possible, then fine-tune to make it usable as a product offering.
The results have been extraordinary. That playbook helped create today’s giants: ChatGPT, Claude, and Gemini are products of this paradigm, and they’ve set a new standard for what humans imagine that machines can do. It’s turned raw web text into reasoning engines, but as all the research labs are now acknowledging, that well is running dry. The web is vast but not infinite, and the frontier has shifted.
The web is tapped out
Most public data that is both high-quality and legally defensible for training has already been mined by the major AI labs. Everything from Wikipedia to Common Crawl, Reddit, GitHub, StackOverflow, PubMed, and arXiv is now standard fare in large-model pretraining.
The industry has hit an information ceiling: simply feeding models more of the same content no longer produces exponential gains. Scaling laws that once held true—performance growing predictably with data, parameters, and compute—are now flattening.
That’s why scaling laws alone are no longer the story. Simply pouring more tokens into ever-larger models is yielding diminishing returns. Running another scrape of the open web won’t produce meaningful performance gains. To keep advancing, the question for the next generation of AI companies isn’t “How much more data can we scrape?” but “How can we create better data?”
OpenAI and Anthropic have both acknowledged this shift publicly. Internal estimates suggest that less than 5% of remaining web-scale content meets quality and licensing standards suitable for frontier training. Meanwhile, synthetic data generation has reached its own limits, with models increasingly overfitting on their own outputs.
The shift to expert data
The next breakthrough frontier isn’t in scale; it’s in specificity. Performance improvements will mainly come from expert-driven, domain-specific data. AI models no longer need just facts; they require judgment, reasoning, and decision-making —the kinds of behaviors learned not from scraped forums but from experts at work. Post-training methods, such as fine-tuning, reinforcement learning with human feedback (RLHF), and Constitutional AI, are where these behaviors are encoded and shaped, not by the internet at large, but by curated, high-quality feedback from subject matter experts.
The shift underway is profound: AI is moving from passively mirroring the internet to actively modeling expert workflows. AI labs are recasting models as systems of intelligence empowered with the ability to utilize tools that can actively solve problems, execute workflows, and collaborate with humans across professional domains. Instead of just ingesting what people say, models must now learn how professionals think and do.
This transition parallels the history of human learning: we begin by observing the world, but mastery is achieved only through mentorship and deliberate practice. Models are following the same curve of judgment, reasoning, and action, and those can’t be learned from scraped web data. They require experts.
From chatbots to systems of intelligence
Today’s LLMs are still largely utilized as chatbots: smart, conversational layers and fact-recall engines built on top of static knowledge. But the labs are already looking further. The next step is systems of intelligence with models that don’t just answer questions, but take action by calling tools, managing workflows, and collaborating with humans.
They see the model as the reasoning core of a larger system, capable of:
- Calling purpose-built tools (e.g., code compilers, search APIs, math solvers).
- Orchestrating 3rd party applications (e.g., CRMs, spreadsheets, databases).
- Managing multi-step workflows with memory, planning, and iteration.
Picture an AI legal associate drafting filings, a medical copilot triaging diagnostic data, or a developer assistant autonomously debugging live code. These systems rely on the same core model but are augmented with specialized data that captures processes, not just content. The new training frontier is not about “what’s true” but “what works.”
To achieve this level of functional reasoning, AI models must be trained on structured datasets that accurately reflect how experts perform tasks in real-world settings, such as writing code, arguing cases, diagnosing patients, negotiating contracts, and managing projects. This type of workflow data is largely absent from the open web.
Why third-party data providers are becoming strategic assets
The next phase of model training is shifting from scraping to partnerships that look more like data licensing and infrastructure deals (not traditional API integrations). Here’s the challenge: Google-scale web data is free and public, but expert workflow data is not.
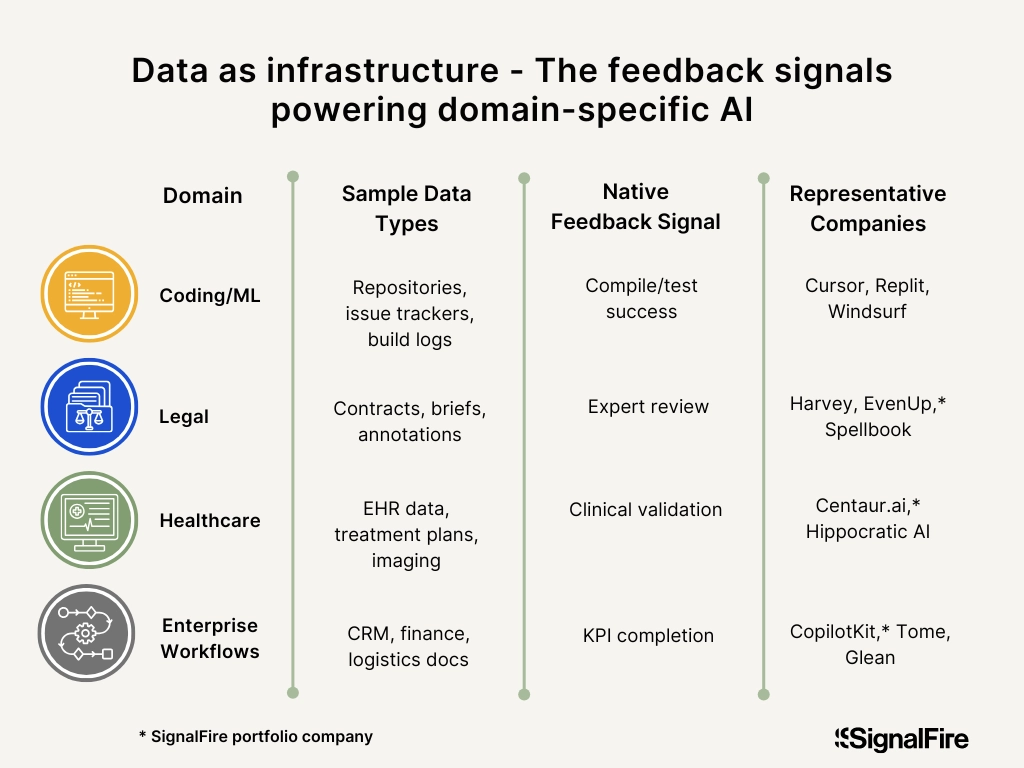
To build models that can expertly operate across domains, AI labs are now negotiating directly with domain gatekeepers and third-party data providers for structured, high-quality datasets, as well as structured workflows and labeled feedback. Here are some examples:
- Coding - Reward functions are easier to construct (e.g., Did the code compile? Did it pass tests?). Labs will license coding environments, bug databases, and structured repositories.
- Legal - Contracts, briefs, memos, and annotations from expert lawyers, where performance can be judged by alignment with precedent or expert review.
- Healthcare - Clinical records, diagnostic decision trees, and treatment pathways, where expert oversight is essential.
- Enterprise Workflows - CRM usage logs, financial modeling templates, supply chain planning documents; data that shows how businesses actually run.
Recent examples point to the emerging playbook:
- OpenAI × Reddit / Stack Overflow / Shutterstock / Financial Times for curated, domain-specific human conversations and imagery.
- Anthropic × Google Cloud for safe code and documentation datasets.
- Grok × X (Twitter) for real-time conversational data.
Each of these represents a recognition: differentiated models will be defined by differentiated data.
This represents a significant opportunity for startups that can curate, label, and structure expert data at scale, becoming indispensable suppliers to frontier labs. It’s like GPUs were in 2022; everyone needed them, and supply defined capability.
The divergence of data
As the major labs mature, we’re seeing data strategies diverge. Each model now trains toward a different product thesis, requiring increasingly specialized datasets:

A company that owns a unique corpus, like high-quality structured clinical decision data or a large-scale annotated coding environment, will find itself not just valuable but essential.
A few predictions for the next 3–5 years:
- Chatbots fade, workflow AI rises: Chatbot interfaces will fade into the background as models integrate into operating systems, enterprise software, and productivity tools, handling multi-step tasks, not just dialogue.
- Data partnerships become strategic chokepoints. Just as GPUs became a chokepoint for training, expert datasets will become a chokepoint for performance. The top labs will continue to sign exclusive data deals in verticals like law, healthcare, and finance.
- Coding and legal will lead adoption. These domains, characterized by structured rules, measurable success, and clear feedback loops, offer natural reward functions and high-value workflows, making them ideal for training models that act, not just predict.
- Healthcare, finance, and science will follow, once safety is proven. Once alignment methods mature and safety is proven, labs will push into regulated, high-stakes domains where expert oversight is mandatory.
- Data infrastructure startups become unicorns. The companies providing compliant, curated, or simulated data environments—especially those with strong RL feedback loops—will become critical "picks and shovels" of the AI economy (RL Environments-as-a-Service).
- Models train on their own product data. As AI applications like Cursor, Harvey, and Perplexity reach breakout scale, they will use in-product user interactions as proprietary RLHF loops and fuel for self-improvement.
The next frontier in AI is in the collective judgment of experts, encoded into data pipelines that teach models how to reason, act, and execute workflows with precision.
The road ahead: From scale to specificity
At SignalFire, we believe the next great AI companies won’t be those training the largest models, but rather the ones creating the best data. The web gave us breadth, and only expert data will give us depth. Our approach is to back data-native infrastructure companies that enable this next era of precision AI.
What we’re looking for:
- Differentiated data ownership or access.
- Domain specificity, where feedback signals are measurable.
- Tight feedback loops that enable continuous RL training.
- Alignment with frontier labs or breakout application companies.
That conviction underpins our early investments in companies like:
- Centaur Labs – Powering safe, expert-labeled data pipelines that train AI across life sciences, consumer, insurance, and software applications. As AI expands into regulated and real-world domains, Centaur provides the trusted data infrastructure that ensures quality, compliance, and reliability at scale.
- [Stealth Startup] – Creating RL environments purpose-built for coding and ML tasks. As AI coding assistants mature, the bottleneck isn’t compute; it’s structured feedback environments where models can practice and improve.
- CopilotKit – CopilotKit provides the infrastructure for enterprises to build custom, in-app copilots and harness real-time interaction data for continuous learning. Every user conversation becomes a training signal, allowing copilots to self-optimize, adapt to context, and grow more capable with scale.
Across these investments, the throughline is clear:
The future of AI performance will be defined not by model size, but by the exclusivity and precision of its training data.
- Synthetic + real hybrid data loops: Companies combining real expert data with AI-generated augmentation will scale faster and safer than those relying on one or the other.
- Data provenance and licensing: Expect a growing ecosystem of startups focused on dataset traceability, attribution, and legal defensibility.
- RL Environments-as-a-Service: Developers will need sandboxed, domain-specific environments (code, simulation, analytics) to fine-tune AI agents safely.
- Regulatory tailwinds: Europe and the U.S. are moving toward data transparency and licensing frameworks that could standardize (and monetize) expert data flows.
The AI frontier is no longer about who can train the biggest model; it’s about who can teach machines to think like experts. As the web’s reservoir runs dry, the next wave of breakthroughs will come from startups building the data engines that encode human judgment, structure, and skill into learning loops. These are the new foundation layers of intelligence, the invisible infrastructure powering every future copilot, agent, and workflow AI.
At SignalFire, we’re backing the founders who see data not as exhaust, but as the new form of IP, those turning expert knowledge into the most valuable training asset of the decade. If you’re building in this space, we want to hear from you. Email me at ryan@signalfire.com.
*Portfolio company founders listed above have not received any compensation for this feedback and may or may not have invested in a SignalFire fund. These founders may or may not serve as Affiliate Advisors, Retained Advisors, or consultants to provide their expertise on a formal or ad hoc basis. They are not employed by SignalFire and do not provide investment advisory services to clients on behalf of SignalFire. Please refer to our disclosures page for additional disclosures.
Related posts

Insurance brokers earn $260B in commissions a year but still run on 1980s tech. Outmarket is the upgrade they’ve been waiting for

SignalFire leads Vector's $10M Series A with HubSpot Ventures to build the first contact-level ad automation platform for B2B

How Fun is building the payments layer for the next generation of global fintechs